S3
Adding S3 data source
The Spark environment, at the company level, allows for only one set of S3 access credentials to be configured at any given time. Consequently, Spark can be set up to access data from either DataGOL's S3 account or a single, specific client's S3 account.
Simultaneous access to data residing in multiple, different S3 accounts (like DataGOL's and a client's at the same time) is NOT supported with the current configuration.
Before you add a S3 data source, ensure to add the following beforehand from the Company section of the Home page.
-
AWS Access Keys
-
AWS Secret Key
-
Region
-
Root Directory
Do the following:
-
On the Home page of DataGOL, from the left navigation panel, click Company.
-
Click the Keys tab.
-
In the AWS Settings box, click the edit button and specify the following details:
-
AWS Access Keys
-
AWS Secret Key
-
Region
-
-
In the Root Directory text box, specify the root directory.
s3 is available only in Amazon AWS infrastructure. S3 is not available as part of Microsoft Azure.
-
From the left navigation panel, click Lakehouse and then click Data Source.
-
From the upper right corner of the page, click the + New Data Source button to start the process of adding a new database.
-
In the New Data Source page, click the S3 icon.
-
Specify the following details to add S3 data source. Once you have connected a data source, the system immediately fetches its schema. After this schema retrieval process is complete you can browse and interact with the tables and data.
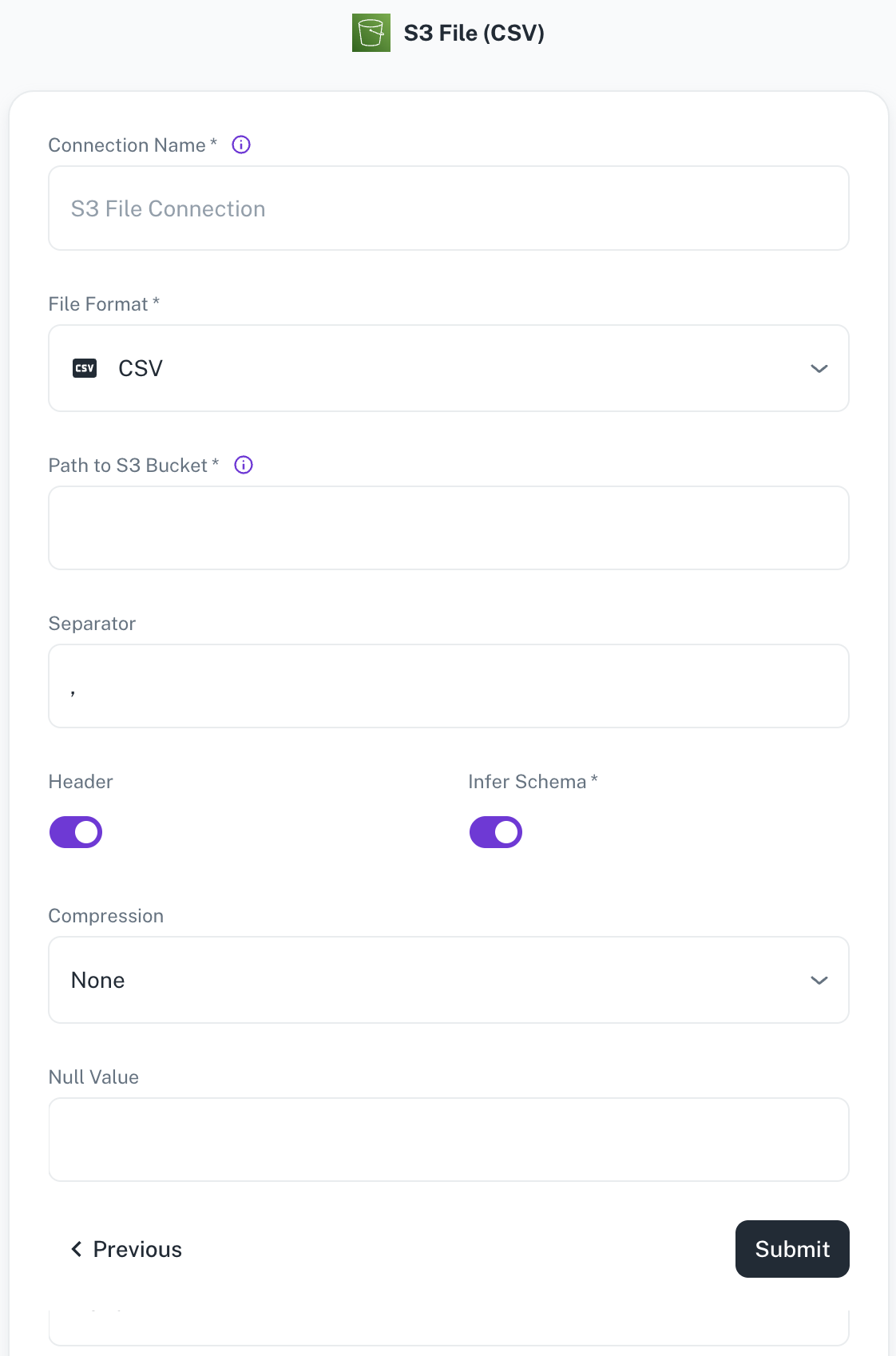
Field Description Connection name Enter a unique name for the connection. File Format Specify any of the following file formats: CSV,Parquet,JSON,Delta(Coming soon)Path to S3 bucket Specify the path of the S3 bucket where the files exist. Example: If file is present in s3a://catalog/db/source/test.csvthen path will becatalog/db. Example format:s3a://catalog/db/Separator Specify the separator character. Header Toggle to indicate if the first row of your CSV contains column headers. Infer Schema Toggle to automatically determine the data type of each column in your data. Compression Select the file compression mode from the following options: Uncompressed,gzip,lzo,brotli,lz4,zstdNull Value A set of case-sensitive strings that should be interpreted as null values. For example, if the value 'NA' should be interpreted as null, enter 'NA' in this field. -
Click Submit.
Spark's configuration limits you to using credentials for only one S3 account at a time. This means that, at the company level, you can either configure Spark with access to your DataGOL S3 account or your S3 account, but not both simultaneously.
Was this helpful?